
Root Cause Analysis: How can an idea that’s wrong be so useful?
What we talk about when we talk about root causes
When it comes to incidents in cloud applications, you hear the phrase “root cause” a lot. In fact, it’s the primary statement of fact for most root cause analysis or incident post-mortems. The root cause (“A”) led to B, which induced C, which begat D, triggering E, all the way down to Very Bad Outcome F. Oh, and we’ll fix A for good, so don’t you worry about F happening in the future.
- “First change made on a router to verify the root cause…root cause found and understood.” (Cloudflare, 2022)
- “The team was confident that they had established the root cause as a software bug in the network configuration management software.” (Google, 2016)
- “Root cause: A bug in the Blob Front-Ends which was exposed by the configuration change made as a part of the performance improvement update.” (Microsoft, 2014)
- “We are observing issues with events ingestion, application UI and web API. We are investigating the potential root cause.” (PagerDuty, 2021)
- “At 7:51 AM PST, we had narrowed the root cause to a couple of candidates…At 9:39 AM PST, we were able to confirm a root cause.” (Amazon AWS, 2021)
But there’s a problem. The whole idea of a “root cause” is just wrong.
The first rule of root cause analysis is that there is no root cause
What you actually find in managing complex systems (cloud apps included) is that there were a variety of causes….and broken defenses…and ignored warnings…and missed hand-offs…and misinterpreted data. As Richard Cook states in his classic essay on complex systems failure,
“Catastrophic failure occurs when small, apparently innocuous failures join to create opportunity for a systemic accident….Because overt failure requires multiple faults, there is no isolated ‘cause’ of an accident.”
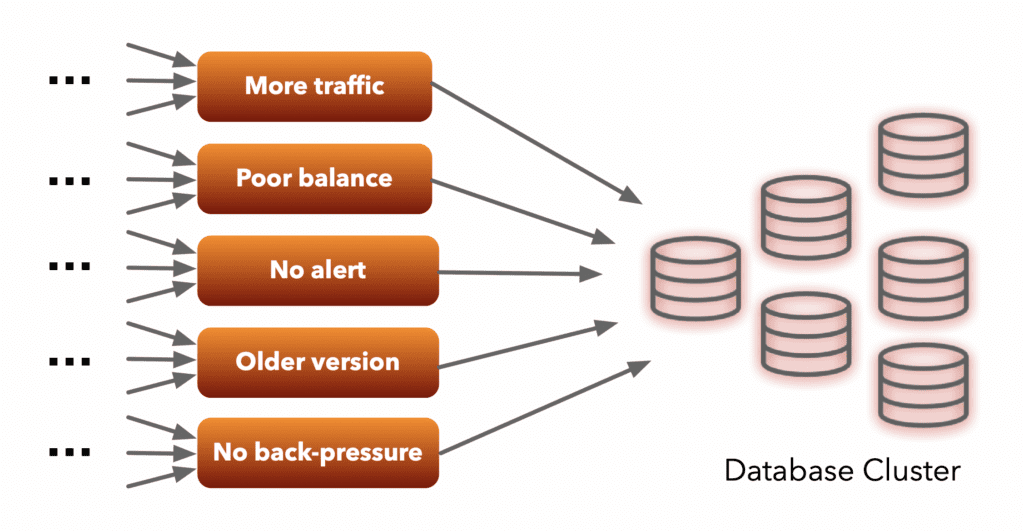
Even a simple technique like “5 whys” will immediately lead to an incredibly intricate, branching set of antecedents, not a single linear path. For example — why did our distributed database max out on CPU and start lagging? Well, it was because 1.) we saw more incoming traffic than usual. But also because…
- 2.) A recent rebalancing concentrated a ton of traffic onto a single node. And…
- 3.) We didn’t have an alert warning us that the node was starting to saturate, giving us time to react. And…
- 4.) We hadn’t upgraded our database version to a more recent one which happens to be more compute-efficient. And….
- 5.) No one had coded a back-pressure protocol back to the client.
None of these factors are direct results of one another in a linear chain; they’re all parallel causes of the failure, with their own (separate) causal chains if you ask the 5 why’s.
If the Idea of a “Root Cause” is wrong, why do we keep using it?
Root cause analysis has to do with the context in which we use “root cause”. We’re not actually trying to reconstruct the full causal trajectory of a system, most of which isn’t relevant to the problem at hand. Instead, we have a more narrow and pragmatic hat on — we’re trying to:
- Resolve an issue
- Prevent it from happening again
This means that when we say “root cause”, we really mean “what could we have done differently” in the past and “what should we do differently” in the future; we’re in the counterfactual and normative modes, not a descriptive one. And note the use of the first person (“we”) in both cases — in ops, “root causes” are actionable causes. It’s a convenient shorthand.
This also means that root causes are subjective, because we each have different scopes of action. If I run my application on top of the cloud, and you work at the cloud provider itself, then we have very different perspectives on why my app failed: I say that I didn’t architect my app to work around inevitable cloud failures — but you’ll say the cloud failure itself wasn’t inevitable at all; it was a result of some factors internal to the cloud that I’m not privy to. Black boxes aren’t root causes; when they fail, that’s on us for not protecting ourselves against an unreliable dependency.
Nothing I’ve said so far should be that surprising to experienced developers and ops engineers. This is all a familiar reality — cloud apps are complex systems; complex systems fail for many reasons; and “root cause” is a handy shortcut for actionable resolutions and prevention.
So if we know all this, why are we still so bad at figuring out cause and effect in our cloud apps when it matters most? 3 simple statistics:
- A 2022 study by Splunk found that the median downtime (MTTR) was more than 5 hours.
- “76% of all performance problems can eventually be traced back to changes in the environment”
- “66% of MTTR is spent on identifying change that is causing a problem.”
Root cause analysis is getting harder; downtimes are long; most downtimes arise from internal changes….and most of that (long) downtime is spent trying to figure out which change was the primary cause.
In other words, when the light turns off, it takes us hours to figure out who flicked what switch.
Observability falls short
This just isn’t good enough. What are we paying for when we buy monitoring and observability — if not a solution to our most urgent/expensive operational issues?

There are two key gaps in our current tools:
- Missing Change Data: In particular, the data of what’s being done to the system. As described above, most incidents are connected to internal changes — in other words, actions which would be fingered as the “root cause” later on. But most observability tools don’t track these changes at all, focusing ever-deeper on the effects without regard for causes.
- Missing Relationship Data: Observability data points are disconnected from each other, with very few system semantics. If service A calls service B, and both emit metrics, these platforms don’t have a good way of telling you that a spike in a metric on one service might have something to do with a spike on another service. Traces connect requests, but don’t track non-request network traffic or non-call dependencies at all (like which process is running in which container in which node in which cluster in which availability zone in which region, and how these different levels interact).
We’re buying data stores when we really need management platforms — platforms that can tie the data together, model component interactions, and connect cause and effect. The current portfolio of operational data (logs, traces, metrics, events) is necessary, but neither sufficient nor efficient for effective root cause analysis— judging by the sad statistics above.
And here’s the thing — if the observability tools aren’t making those connections between cause and effect, someone has to — or more likely, multiple teams of people who have their separate parts of the application in their heads. It’s like the parable of the blind men trying to describe an elephant, who have trouble reconciling their limited perspectives.

Feels like…a lot of conference bridges I’ve been on
We’re losing sight of the goals of observability and have gotten lost in the data weeds. Our goal is to manage and operate a cloud application, not to hoard piles of disconnected data that don’t actually help us get up and running.
And this “troubleshooting tax” actually gets higher with more advanced DevOps processes like continuous deployment — because we’re throwing expensive/manual resources that don’t scale well (people) against demand that scales indefinitely (application complexity).
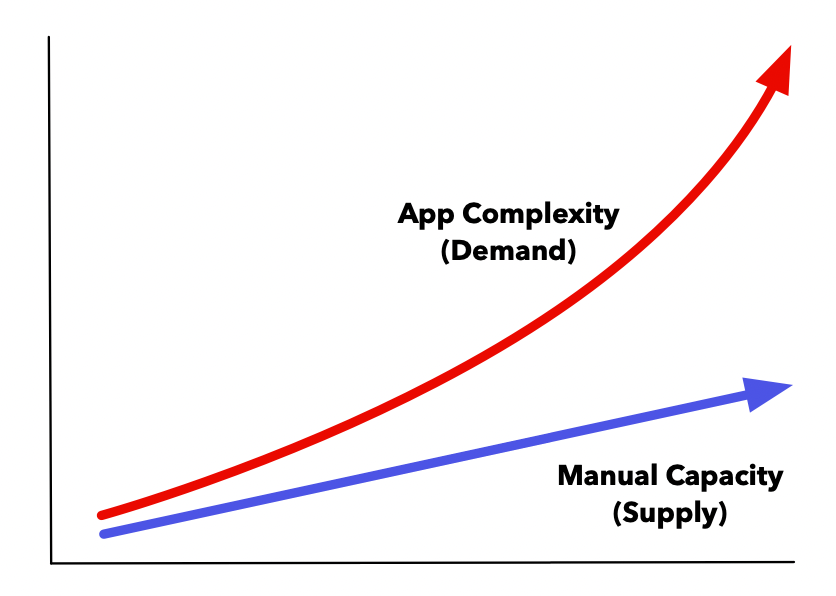
It’s a costly mismatch, and it’s only getting worse.
What’s Next?
If we wanted to improve that performance on managing the application (not just ingestion rates), what kind of system would we need? Well, we’d need to fill the gaps mentioned above:
- Change Management System of Record: If changes are the actionable causes of most incidents (~75%), and yet this data isn’t collected or centralized, the first part of the solution would be a change management system of record, tracking what’s actually been done (not just planned or ticketed) to the application itself.
- Relationship System of Record: The second part would be a system of record for the relationships between metrics, and events, and logs, and traces, and entities, and changes — forming a graph of the application that can model cause and effect through incidents in real-time, the same paths traced slowly and laboriously by the on-call team (and developers) today.
This is what we need to break the supply/demand mismatch, scale our apps without scaling the burden on our teams, and manage our applications rather than overreacting to fragmented data silos after the fact. This is what’s next.





